Numba를 이용한 Cuda 프로그램
1. Cuda 정리[1]
이 절에서는 간단한 Cuda 프로그래밍 내용을 정리한다.
1.1. Memory hierarchy
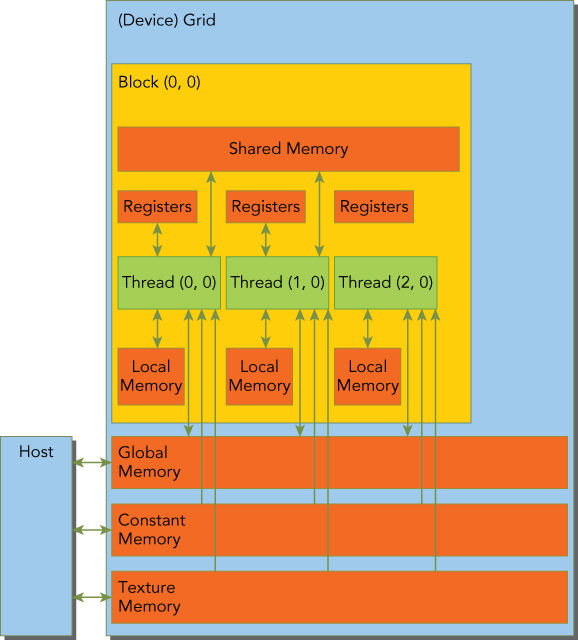
- Registers
- Thread 간에도 공유되지 않는다.
- 함수에서 선언한 변수를 저장한다.
- 함수에서 선언한 변수의 크기가 Thread의 Register개수를 넘을 경우 Local 메모리에 위치한다.
- Shared memory
- __shared__를 이용하여 선언한다.
- Local, Global memory보다 지연시간이 적다.
- Block내의 Thread간 공유된다.
- __syncThreads()으로 Shared memory의 Coherent를 유지한다.
- L1 cache와 하드웨어를 공유하고 할당량은 cudaFuncSetCache함수를 이용하여 설정가능한다.
- Local memory
- Registers의 공간 부족으로 Cache에 위치한 변수
- Constant memory
- __constant__를 이용하여 선언한다.
- Global scope 선언되어야 한다.
- Kernel 실행 전 cudaMemcpyToSymbo로 값을 설정하여야한다.
- Texture memory
- Read Only
- 2D Spatial Locality에 최적회 되어 있다.
- Global memory
- __device__식별자를 이용하여 선언하거나 Host에서 cudaMalloc을 이용한다.
- CUDA Variable and Type Qualifier
| Qualifier | Variable Name | Memory | Scope | Lifespan |
|---|---|---|---|---|
| float var | Register | Thread | Thread | |
| float var[100] | Local | Thread | Thread | |
| shared | float var | Shared | Block | Block |
| device | float var | Global | Global | Application |
| constant | float var | Constant | Global | Application |
- Salient Features of Device Memory
| Memory | On/Off Chip | Cached | Access | Scope | Lifetime |
|---|---|---|---|---|---|
| Register | On | n/a | R/W | 1 thread | Thread |
| Local | Off | Yes | R/W | 1 thread | Thread |
| Shared | On | n/a | R/W | All threads in block | Block |
| Global | Off | † | R/W | All threads + host | Host allocation |
| Constant | Off | Yes | R | All threads + host | Host allocation |
| Texture | Off | Yes | R | All threads + host | Host allocation |
1.2. Host <-> Device
Host와 device의 변수가 동일한 파일에 선언되어 있어도 직접적인 참조는 불가능한다. 배열의 경우 cudaAlloc으로 할당된 포인터와 cudaMemcpy를 이용하여 Host와 device간 데이터를 교환할 수 있다. 하지만 Global scope에 __device__로 선언된 변수의 경우는 변수의 주소값과 cudaMemcpy를 이용하여 값을 전송 할 수 없다. 이런 경우에는 cudaGetSymboAddress를 이용하여 포인터를 얻어와서 cudaMemcpy를 이용하거나 cudaMemcpyToSymbol 명령을 이용하여 한다.
#include <cuda_runtime.h>
#include <stdio.h>
__device__ float devData;
__global__ void checkGlobalVariable() {
devData +=2.0f;
}
int main(void) {
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
// 위의 처럼 devData에 저장하거나
float *dptr = NULL;
cudaGetSymbolAddress((void**)&dptr, devData);
cudaMemcpy(dptr, &value, sizeof(float), cudaMemcpyHostToDevice);
//
checkGlobalVariable <<<1, 1>>>();
cudaMemcpyFromSymbol(&value, devData, sizeof(float));
cudaDeviceReset();
return EXIT_SUCCESS;
}
1.3. Pinned Memory
CPU에서 선언한 배열의 경우 Pageable 메모리 형태로 생성되므로 Device로 데이터를 전송 할때 Overhead가 생성된다. Host에서 사용할 메모리를 cudaMallocHost/cudaFreeHost를 이용하면 Pinned Memory(Non-pageable)로 선언되므로 Overhead를 줄일 수 있다. Pinned Memory가 많을 수록 host의 전체 성능이 저하 될 수 있으므로 시스템과 프로그램 상황에 맞게 조절되어야 한다.
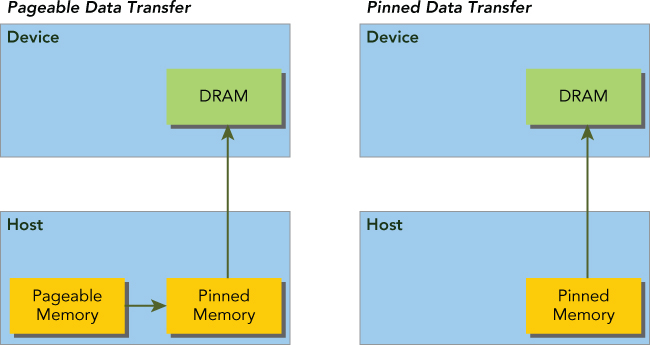
1.4. Zero-Copy Memory
일반적으로는 Host<->Device간의 데이터를 직접 주고 받을 수 없지만 Zero-Copy memory로 선언된 영역에 대해서는 Host와 device가 접근할 수 있다. cudaHostAlloc/cudaFreeHost를 이용하여 선언/해제 할 수 있다.
Zero-Copy Memory의 장점은 다음과 같다.
- Leveraging host memory when there is insufficient device memory
- Avoiding explicit data transfer between the host and device
- Improving PCIe transfer rates
큰 배열의 경우 cudaMalloc을 사용하는 것이 훨씬 효율적이다.
2. 코드
2.1. 시간 측정 함수
class Timer:
"""클래스 생성 시점부터 소멸 시점까지의 시간을 출력한다."""
def __init__(self, func_name: str='this func'):
self.func_name: str = func_name
self.time_start: float = 0.0
def __enter__(self):
import sys
import time
print(f'{self.func_name} ==>', end=' ')
sys.stdout.flush()
self.time_start = time.perf_counter_ns()
return self
def __exit__(self, *args):
import time
time_end = time.perf_counter_ns()
interval = (time_end - self.time_start) / 1e9
print(f'Elapsed time: {interval:.8f} sec')
2.2. Device Info [2]
import pycuda.driver as drv
drv.init()
print('Detected {} CUDA Capable device(s) \n'.format(drv.Device.count()))
for i in range(drv.Device.count()):
dev = drv.Device(i)
print(f'Device {i}: {dev.name()}')
compute_capability = float('%d.%d' % dev.compute_capability())
print(f' Compute Capability: {compute_capability}')
print(f' Total Memory: {dev.total_memory() // (1024**2)} MB')
dev_attr_tuples = dev.get_attributes().items()
dev_attributes = {}
for k, v in dev_attr_tuples:
dev_attributes[str(k)] = v
num_mp = dev_attributes['MULTIPROCESSOR_COUNT']
cuda_cores_per_mp = {5.0 : 128,
5.1 : 128,
5.2 : 128,
6.0 : 64,
6.1 : 128,
6.2 : 128}[compute_capability]
print(f' Multiprocessors: {num_mp}')
print(f' CUDA Cores Per Multiprocessor: {cuda_cores_per_mp}')
print(f' Total CUDA Cores: {num_mp * cuda_cores_per_mp}')
dev_attributes.pop('MULTIPROCESSOR_COUNT')
for k in dev_attributes.keys():
print(f' {k}: {dev_attributes[k]}')
Detected 1 CUDA Capable device(s)
Device 0: GeForce GTX 850M
Compute Capability: 5.0
Total Memory: 2004 MB
Multiprocessors: 5
CUDA Cores Per Multiprocessor: 128
Total CUDA Cores: 640
ASYNC_ENGINE_COUNT: 1
CAN_MAP_HOST_MEMORY: 1
CLOCK_RATE: 901500
COMPUTE_CAPABILITY_MAJOR: 5
COMPUTE_CAPABILITY_MINOR: 0
COMPUTE_MODE: DEFAULT
CONCURRENT_KERNELS: 1
ECC_ENABLED: 0
GLOBAL_L1_CACHE_SUPPORTED: 0
GLOBAL_MEMORY_BUS_WIDTH: 128
GPU_OVERLAP: 1
INTEGRATED: 0
KERNEL_EXEC_TIMEOUT: 1
L2_CACHE_SIZE: 2097152
LOCAL_L1_CACHE_SUPPORTED: 1
MANAGED_MEMORY: 1
MAXIMUM_SURFACE1D_LAYERED_LAYERS: 2048
MAXIMUM_SURFACE1D_LAYERED_WIDTH: 16384
MAXIMUM_SURFACE1D_WIDTH: 16384
MAXIMUM_SURFACE2D_HEIGHT: 65536
MAXIMUM_SURFACE2D_LAYERED_HEIGHT: 16384
MAXIMUM_SURFACE2D_LAYERED_LAYERS: 2048
MAXIMUM_SURFACE2D_LAYERED_WIDTH: 16384
MAXIMUM_SURFACE2D_WIDTH: 65536
MAXIMUM_SURFACE3D_DEPTH: 4096
MAXIMUM_SURFACE3D_HEIGHT: 4096
MAXIMUM_SURFACE3D_WIDTH: 4096
MAXIMUM_SURFACECUBEMAP_LAYERED_LAYERS: 2046
MAXIMUM_SURFACECUBEMAP_LAYERED_WIDTH: 16384
MAXIMUM_SURFACECUBEMAP_WIDTH: 16384
MAXIMUM_TEXTURE1D_LAYERED_LAYERS: 2048
MAXIMUM_TEXTURE1D_LAYERED_WIDTH: 16384
MAXIMUM_TEXTURE1D_LINEAR_WIDTH: 134217728
MAXIMUM_TEXTURE1D_MIPMAPPED_WIDTH: 16384
MAXIMUM_TEXTURE1D_WIDTH: 65536
MAXIMUM_TEXTURE2D_ARRAY_HEIGHT: 16384
MAXIMUM_TEXTURE2D_ARRAY_NUMSLICES: 2048
MAXIMUM_TEXTURE2D_ARRAY_WIDTH: 16384
MAXIMUM_TEXTURE2D_GATHER_HEIGHT: 16384
MAXIMUM_TEXTURE2D_GATHER_WIDTH: 16384
MAXIMUM_TEXTURE2D_HEIGHT: 65536
MAXIMUM_TEXTURE2D_LINEAR_HEIGHT: 65536
MAXIMUM_TEXTURE2D_LINEAR_PITCH: 1048544
MAXIMUM_TEXTURE2D_LINEAR_WIDTH: 65536
MAXIMUM_TEXTURE2D_MIPMAPPED_HEIGHT: 16384
MAXIMUM_TEXTURE2D_MIPMAPPED_WIDTH: 16384
MAXIMUM_TEXTURE2D_WIDTH: 65536
MAXIMUM_TEXTURE3D_DEPTH: 4096
MAXIMUM_TEXTURE3D_DEPTH_ALTERNATE: 16384
MAXIMUM_TEXTURE3D_HEIGHT: 4096
MAXIMUM_TEXTURE3D_HEIGHT_ALTERNATE: 2048
MAXIMUM_TEXTURE3D_WIDTH: 4096
MAXIMUM_TEXTURE3D_WIDTH_ALTERNATE: 2048
MAXIMUM_TEXTURECUBEMAP_LAYERED_LAYERS: 2046
MAXIMUM_TEXTURECUBEMAP_LAYERED_WIDTH: 16384
MAXIMUM_TEXTURECUBEMAP_WIDTH: 16384
MAX_BLOCK_DIM_X: 1024
MAX_BLOCK_DIM_Y: 1024
MAX_BLOCK_DIM_Z: 64
MAX_GRID_DIM_X: 2147483647
MAX_GRID_DIM_Y: 65535
MAX_GRID_DIM_Z: 65535
MAX_PITCH: 2147483647
MAX_REGISTERS_PER_BLOCK: 65536
MAX_REGISTERS_PER_MULTIPROCESSOR: 65536
MAX_SHARED_MEMORY_PER_BLOCK: 49152
MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 65536
MAX_THREADS_PER_BLOCK: 1024
MAX_THREADS_PER_MULTIPROCESSOR: 2048
MEMORY_CLOCK_RATE: 1001000
MULTI_GPU_BOARD: 0
MULTI_GPU_BOARD_GROUP_ID: 0
PCI_BUS_ID: 1
PCI_DEVICE_ID: 0
PCI_DOMAIN_ID: 0
STREAM_PRIORITIES_SUPPORTED: 1
SURFACE_ALIGNMENT: 512
TCC_DRIVER: 0
TEXTURE_ALIGNMENT: 512
TEXTURE_PITCH_ALIGNMENT: 32
TOTAL_CONSTANT_MEMORY: 65536
UNIFIED_ADDRESSING: 1
WARP_SIZE: 32
2.3. Sum
GPU는 Code 최적화에 따라서 연산 시간에 많은 차이를 보인다. 간단한 SUM Code 조차도 CUDA에서 최적화 하는 것이 쉽지 않은 일이다(GPU_SUM.pdf). 하지만 Numba의 reduce를 이용하면 SUM을 CUDA로 쉽게 Coding 할 수 있다.
2.3.1. Sum Kernel Code using reduce of numba
from numba import cuda
from numba.cuda import to_device
import numpy as np
@cuda.reduce
def sum_reduce(a, b):
return a + b
2.3.2. Sum Host Code using reduce of numba
import math
import numpy as np
from numpy import float32
from mkl_random import standard_normal
n_sample = 2 ** 26
data = float32(standard_normal(n_sample))
d_data = to_device(data.copy())
with Timer('Sum By CPU'):
sum_cpu = np.sum(data)
_ = sum_reduce(data)
with Timer('Sum By GPU'):
sum_gpu = sum_reduce(d_data)
print(f'CPU Result: {sum_cpu}')
print(f'GPU Result: {sum_gpu}')
Sum By CPU ==> Elapsed time: 0.02662821 sec
Sum By GPU ==> Elapsed time: 0.01087535 sec
CPU Result: 4220.08349609375
GPU Result: 4220.095703125
2.3.3. Sum Code using reduction
GPU_SUM.pdf의 예제를 Numba에서도 구현 해 볼 수 있다.
# Kernel Code
from numba import cuda
from numba.cuda import to_device
import numpy as np
@cuda.jit("void(float32[:], float32[:], int64)")
def sum_kernel(out, data, n):
tid = cuda.threadIdx.x
idx = cuda.grid(1)
idx_block_start = cuda.blockIdx.x * cuda.blockDim.x
if idx >= n:
return
stride = cuda.blockDim.x // 2
while stride > 0:
if tid < stride and (idx_block_start + tid + stride) < n:
data[idx_block_start + tid] += data[idx_block_start + tid + stride]
cuda.syncthreads()
stride //= 2
if (tid == 0):
out[cuda.blockIdx.x] = data[idx_block_start]
# Host Code
import math
import numpy as np
from numpy import float32
from mkl_random import standard_normal
n_sample = 2 ** 26
data = float32(standard_normal(n_sample))
d_data = to_device(data.copy())
with Timer('Sum By CPU'):
sum_cpu = np.sum(data)
threadsperblock = 128
blockspergrid = math.ceil(n_sample / threadsperblock)
out_of_gpu = cuda.device_array(blockspergrid, float32)
sum_kernel[blockspergrid, threadsperblock](out_of_gpu, data, n_sample) # For Compile
with Timer('Sum By GPU'):
sum_kernel[blockspergrid, threadsperblock](out_of_gpu, d_data, n_sample)
out_from_gpu = out_of_gpu.copy_to_host()
sum_gpu = np.sum(out_from_gpu)
print(f'CPU Result: {sum_cpu}')
print(f'GPU Result: {sum_gpu}')
Sum By CPU ==> Elapsed time: 0.02695911 sec
Sum By GPU ==> Elapsed time: 0.05354665 sec
CPU Result: 458.8485107421875
GPU Result: 458.8516845703125
3. 참고자료
[1] Professional CUDA C Programming
[2] Dr. Brian Tuomanen. (2018). Chapter3, Hands-On GPU Programming with Python and CUDA (39).